Diese beeindruckenden Zahlen werden durch verschiedene Untersuchungen unterstützt, zum Beispiel von der Oxford University in ihrem Bericht „The OEC: Facts about the language“. Weitere Nachweise findest Du hier.
Doch unsere Neugier war noch nicht gestillt, deshalb haben wir aus drei Gründen eine eigene Untersuchung durchgeführt:
Im Grunde sind das alle Sätze, die weltweit in dieser Sprache gesprochen wurden. Natürlich haben wir nicht überall Mikrofone, aber das brauchen wir auch nicht, denn tausende Menschen nehmen täglich Gespräche auf und teilen diese im Internet.
Wir haben so Transkripte von tausenden Podcast-Episoden und YouTube-Videos gesammelt, die Gespräche von Personen mit unterschiedlichen Berufen, Interessen und Hintergründen darstellen – insgesamt mehr als eine Million Stunden Konversation zwischen echten Menschen. Diese riesige Textsammlung ist unsere Stichprobe der gesprochenen Sprache.
Mit einem Python-Skript wurden die Texte zerlegt (Tokenization) und auf ihre Grundform gebracht (Lemmatization) unter Verwendung von SpaCy. “to run”, “running” und “runs” sind alles Formen von “to run” und werden also zusammengefasst. Lautworte wie 'Skrrt' und fehlerhafte Wörter wurden entfernt, indem wir diese mit einem umfangreichen Wörterbuch verglichen haben das möglichst alle echten Wörter beinhaltet - Die Wörter, die nicht darin vorkommen, haben wir entfernt.
Die übergebliebenen Wörter wurden dann gezählt und nach Häufigkeit sortiert. So entstand unsere Liste der Top Wörter. Insgesamt 49.080 – so viele einzigartige Wörter bzw. Lemmas fanden wir in unserem Datensatz.
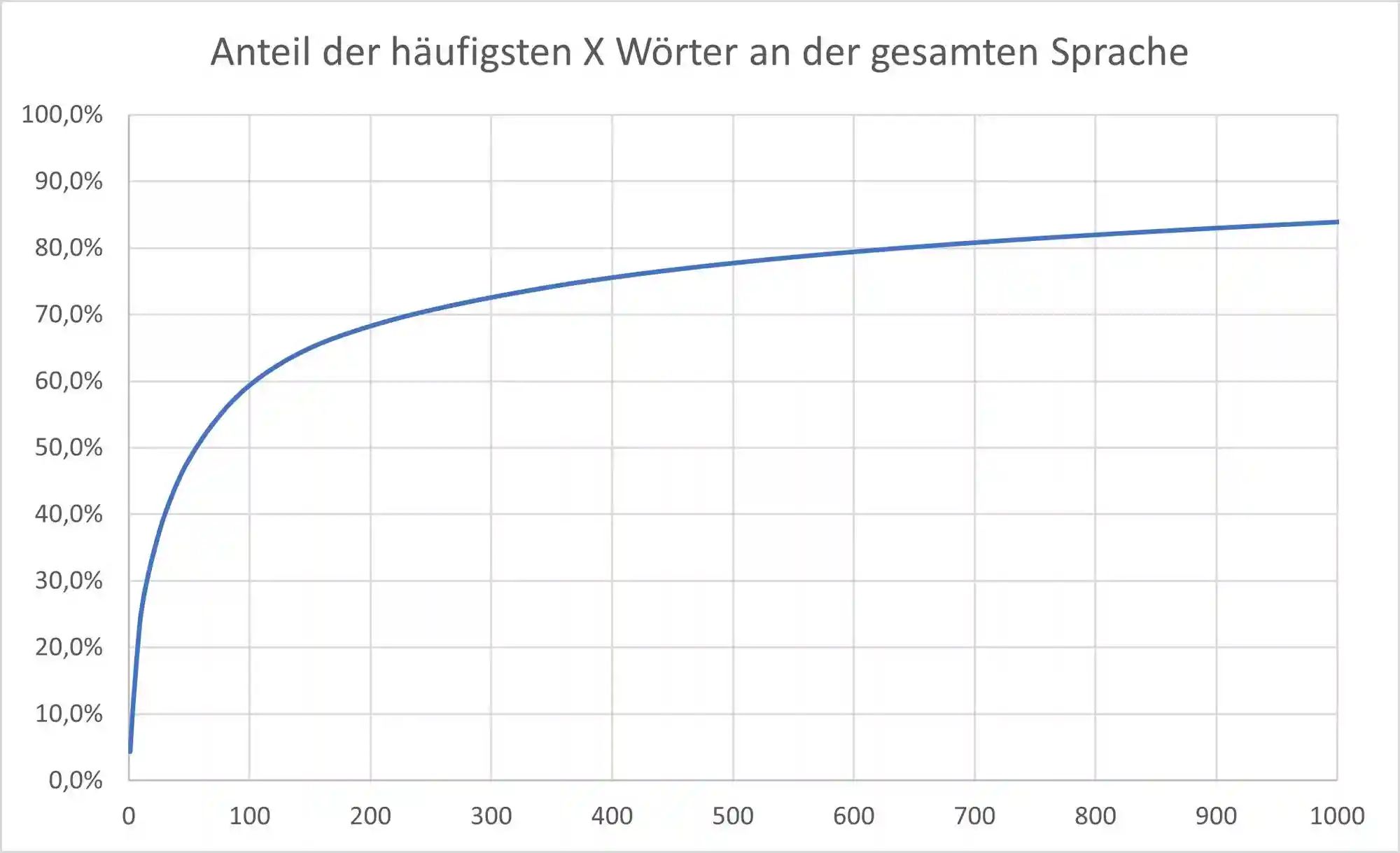
Das häufigste Wort ist „The“, welches 2.478.363 Mal in unserem Datensatz bestehend aus insgesamt 56.796.555 Wörtern vorkam. Das bedeutet, 4,4% aller Wörter in unserem Datensatz waren das Wort „The“.
Platz zwei ist „and“ mit 1.736.450 Nennungen und Platz drei ist „I“ mit 1.649.606. Diese Top 3 Wörter kamen zusammen also 5.864.419 mal vor und machen damit bereits 10,3% der 56.796.555 Wörter aus.
Studien wie die der Oxford University kamen zu ähnlichen Ergebnissen, wie wir: Wenige Wörter machen einen großen Anteil der gesprochenen Sprache aus. Diese Studien haben allerdings unterschiedliche Datensätze verwendet und daher geringfügig andere Ergebnisse.
Während Oxford zu einem großen Teil akademische Journale und Zeitungen einbezog, war der Anteil an Fachliteratur bei uns geringer, denn wir fokussierten wir uns primär auf tatsächlich gesprochene Sprache. Deshalb enthalten die untersuchten Textsammlungen andere Studien wohl teilweise mehr seltene Wörter als unsere, wie z.B. „Dinatriumdihydrogendiphosphat“, welches selten geschrieben und noch seltener gesprochen wird.
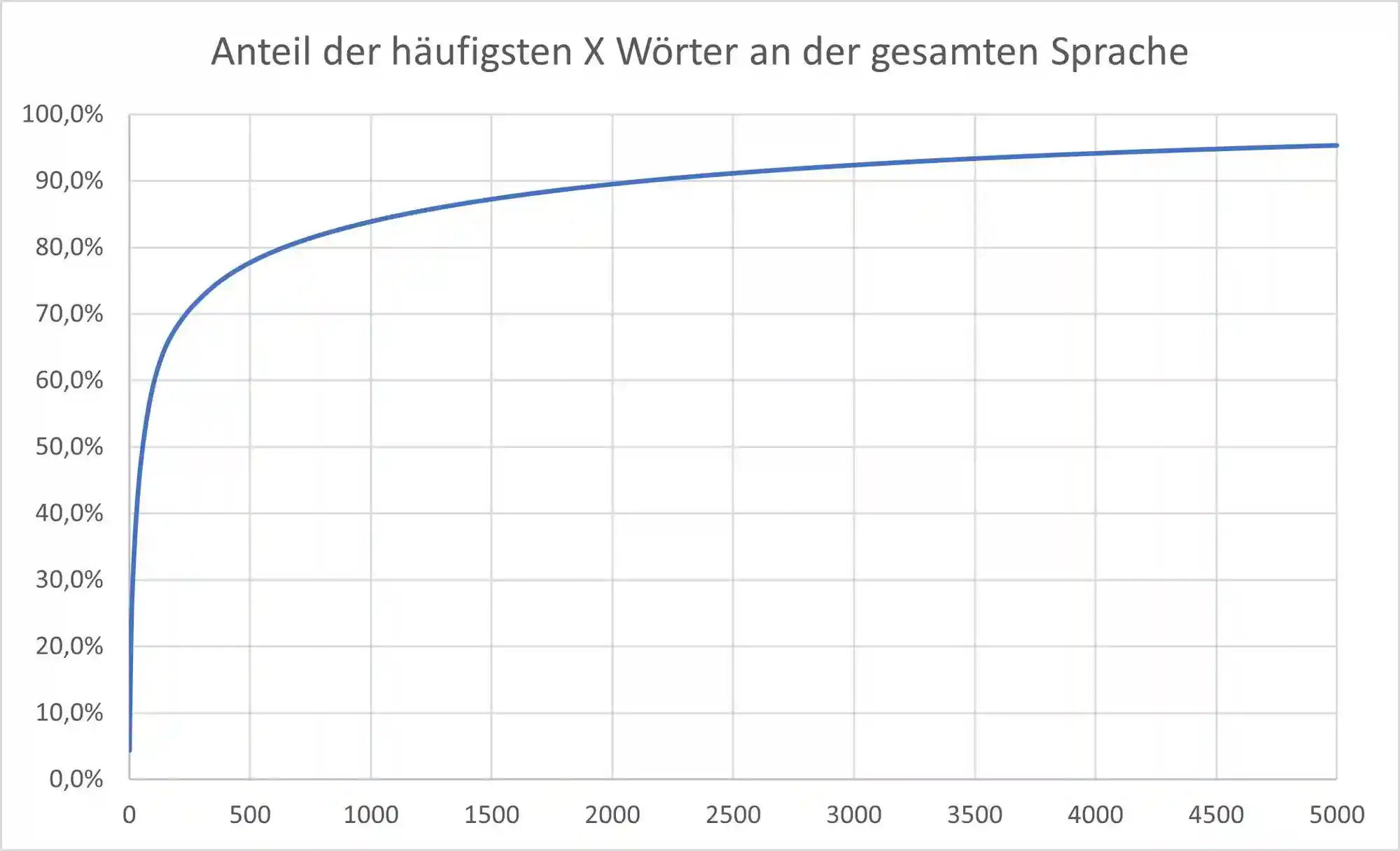
Während andere Untersuchungen z.B zu der Erkenntnis kamen, dass die Top 100 Wörter 50% und die Top 1000 Wörter 80% der Sprache ausmachen, kamen wir sogar auf 59,4% und 84,3%.
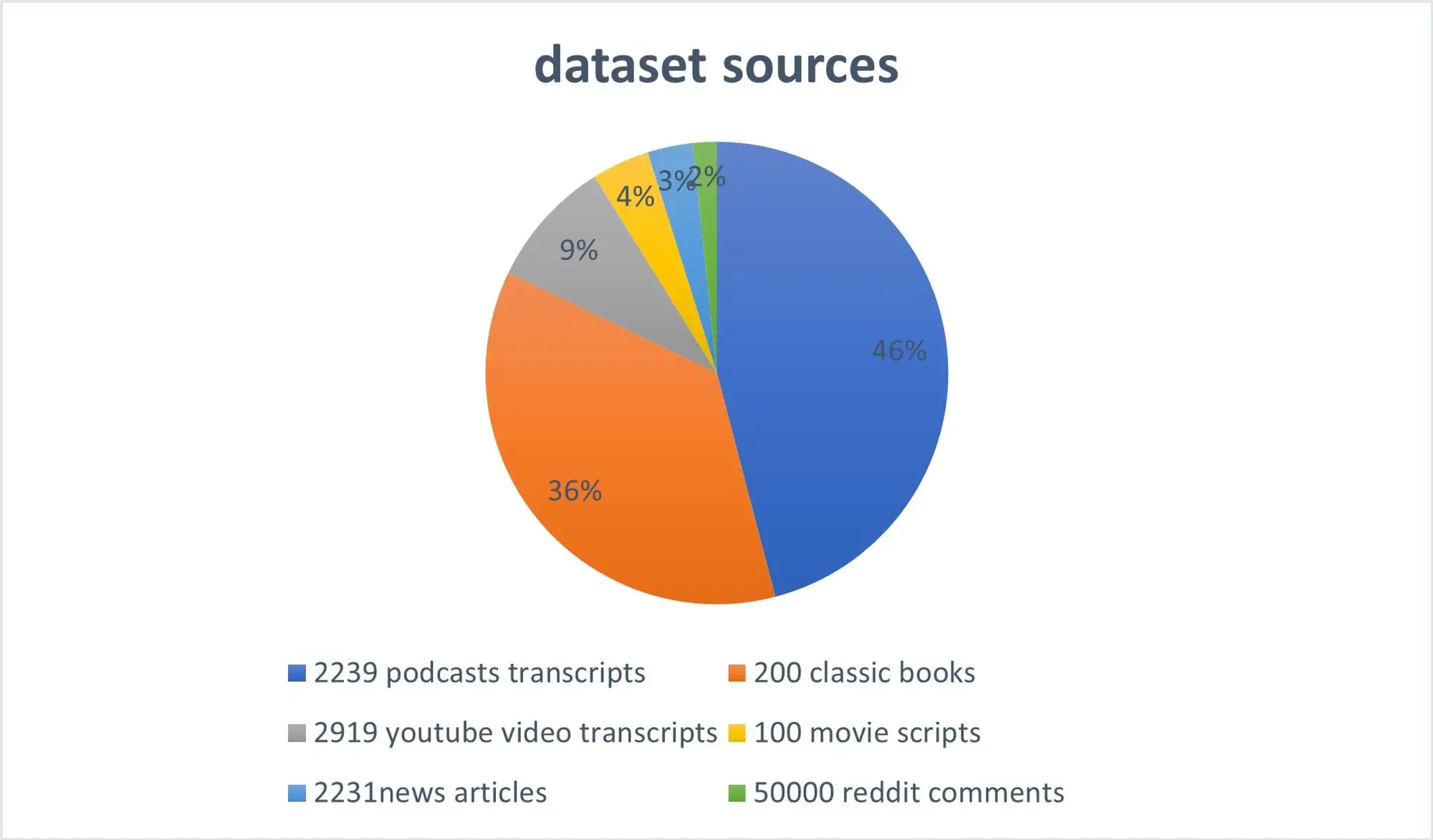
Eine detailliertere Gliederung unseres Datensatzes findest du hier:
Datensatz-Übersicht (englisch)