These impressive numbers are supported by various studies, for example by Oxford University in their report “The OEC: Facts about the language”. You can find more evidence here.
But our curiosity was not satisfied, so we conducted our own research for three reasons:
Basically, it encompasses all sentences spoken worldwide in this language. Of course, we don’t have microphones everywhere, but we don’t need them, because thousands of people record conversations daily and share them on the internet.
We have collected transcripts of thousands of podcast episodes and YouTube videos, representing conversations from people with different professions, interests, and backgrounds – over a million hours of conversation between real people in total. This vast collection of texts is our sample of the spoken language.
The texts were tokenized and lemmatized using a Python script and SpaCy. “to run”, “running”, and “runs” are all forms of “to run” and are therefore grouped together. Onomatopoeic words like 'Skrrt' and incorrect words were removed by comparing them to a comprehensive dictionary that includes almost all real words – words not found in it were removed.
The remaining words were then counted and sorted by frequency, resulting in our list of top words. In total, we found 49,080 unique words or lemmas in our dataset.
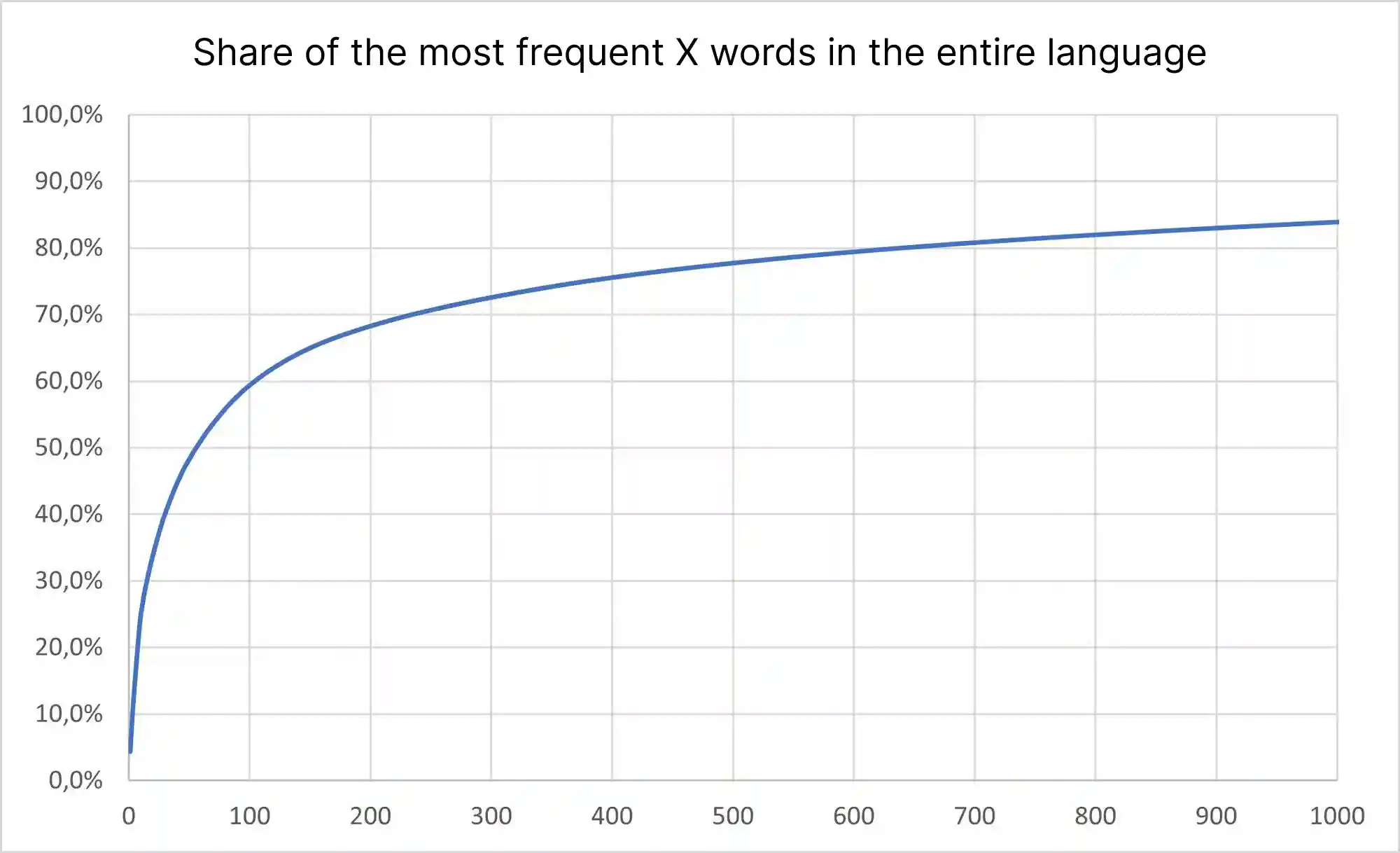
The most frequent word is “The”, which appeared 2,478,363 times in our dataset consisting of a total of 56,796,555 words. This means that 4.4% of all words in our dataset were the word “The”.
The second most frequent word is “and” with 1,736,450 mentions and the third is “I” with 1,649,606. These top 3 words together appeared 5,864,419 times, accounting for 10.3% of the 56,796,555 words.
Studies like those from Oxford University came to similar results as we did: Few words make up a large portion of the spoken language. However, these studies used different datasets and therefore have slightly different results.
While Oxford included a large proportion of academic journals and newspapers, our share of specialized literature was lower because we focused primarily on actual spoken language. Therefore, the text collections examined by other studies may include more rare words than ours, such as “dinatriumdihydrogendiphosphate”, which is rarely written and even less often spoken.
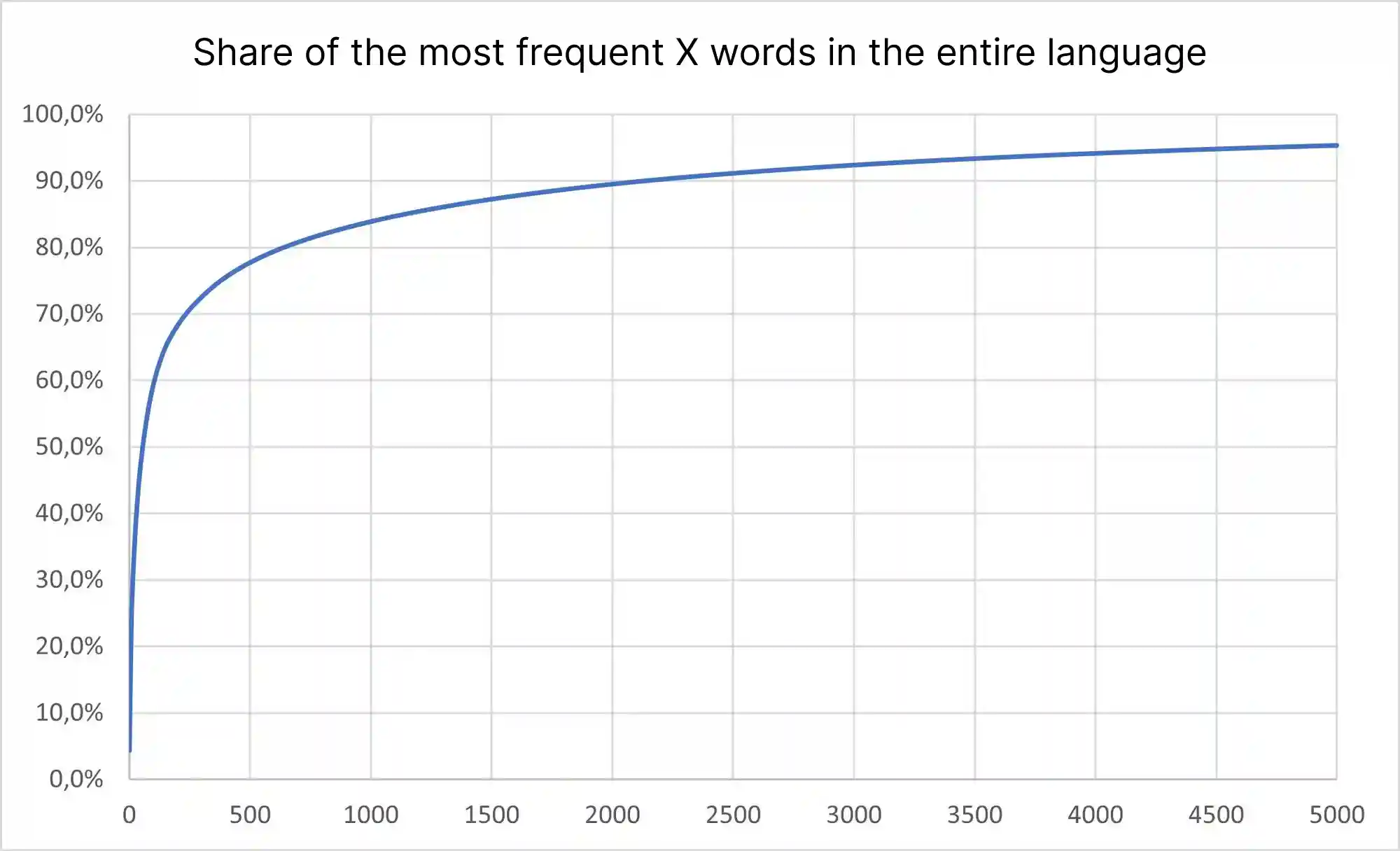
While other studies found that the top 100 words make up 50% and the top 1000 words make up 80% of the language, we found 59.4% and 84.3%.
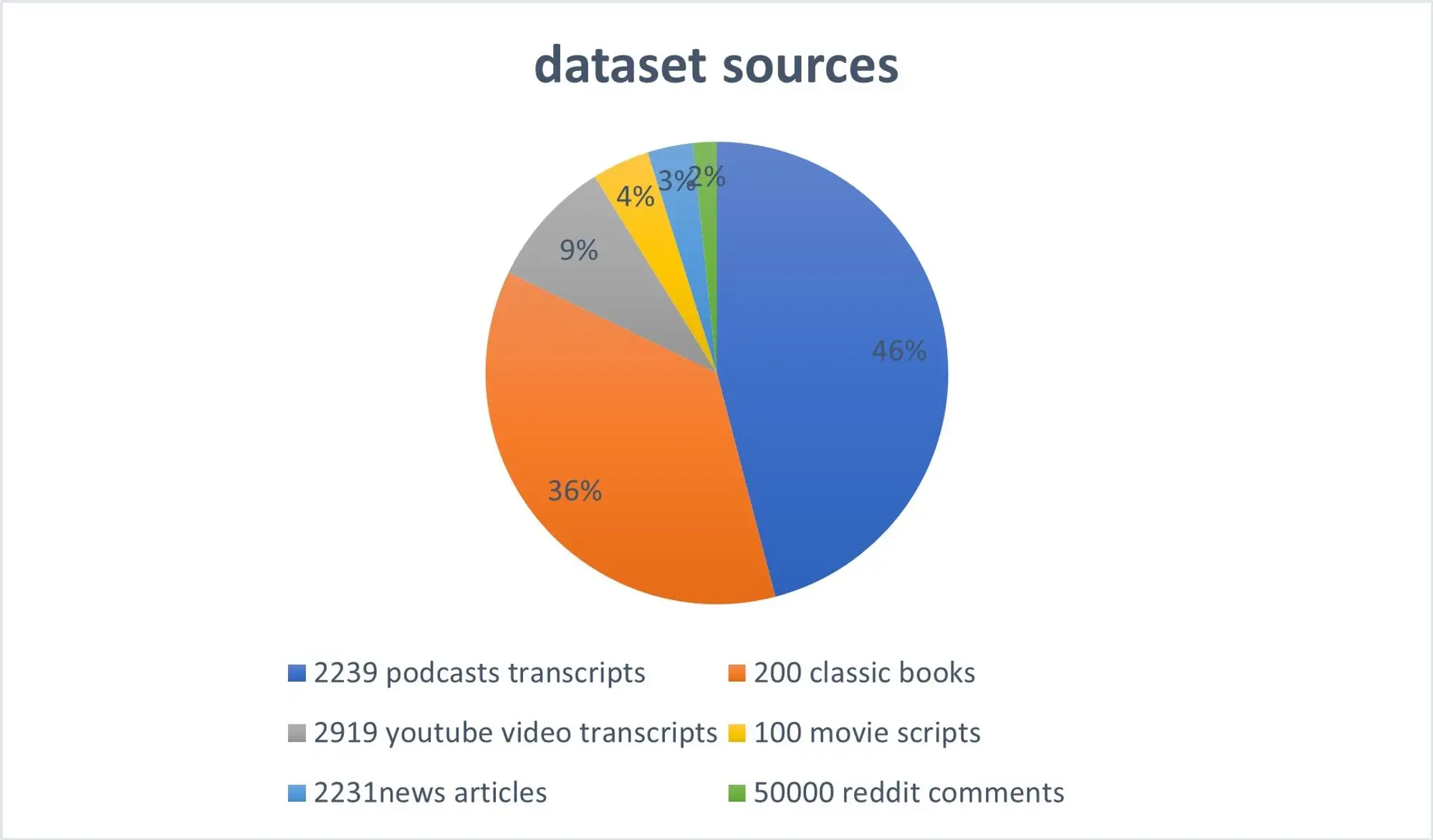
You can find a more detailed breakdown of our dataset here:
Dataset Overview